LLM推論のスケーリング:GKEとManaged Lustreによるマルチノード KVキャッシュオフロード Scaling LLM Inference: Multi-Node KV Cache Offloading with GKE & Managed Lustre
元記事を読む 鮮度 OK
AI 3 行サマリ
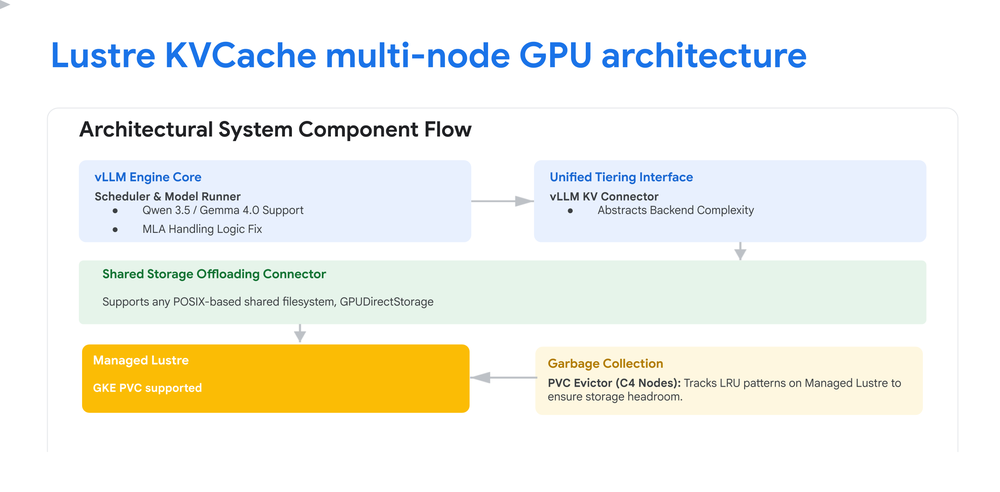
- GKEとManaged Lustreを組み合わせ、LLM推論のKVキャッシュをマルチノードにオフロードするアーキテクチャを解説。
- 長いコンテキスト長や高スループットの推論ワークロードを実用的な規模でスケールさせる手法を紹介している。
English summary
- This post demonstrates how to scale LLM inference by offloading KV caches across multiple nodes using GKE and Google Cloud Managed Lustre, making it practical to serve long-context models at high throughput.
元記事を読む  cloud.google.com
cloud.google.com
本ページの本文・要約は AI による自動生成です。正確性は元記事 (cloud.google.com) をご確認ください。


